J’ai fait une application pour le cours du collège : Implémentation de solutions infonuagiques pour le stockage de données.
J’aime beaucoup faire ces exercices car ils nous permettent d’entrer dans l’univers du Cloud et de ses avantages.
Je devais mettre en place un lac de données qui comprend trois zones de stockage de données analytiques en fonction de leur forme et de leur étape dans le cycle de vie. Elles ont donc été créées :
Zone brute : cette zone a été utilisée pour stocker les données dans leur forme et leur format d’origine, sans aucune transformation.
Zone normalisée : les données de cette zone seront converties de leur format d’origine au format Parquet.
Zone de consommation : cette zone a été définie comme la zone finale, où les utilisateurs et les applications consommeront les données. Les transformations et les règles de gestion seront appliquées dans cette zone.
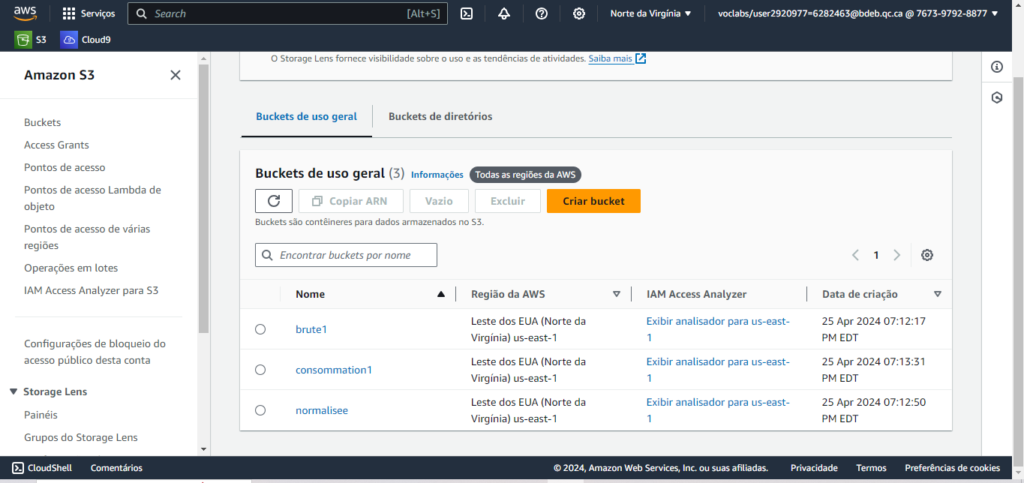
J’ai implémenté les trois zones en utilisant les services AWS, en utilisant les mots « brute1″, » normalisée » et » consommation1 » dans les noms des zones.
Dans la zone brute, j’ai téléchargé le fichier CSV sur lequel j’allais travailler.
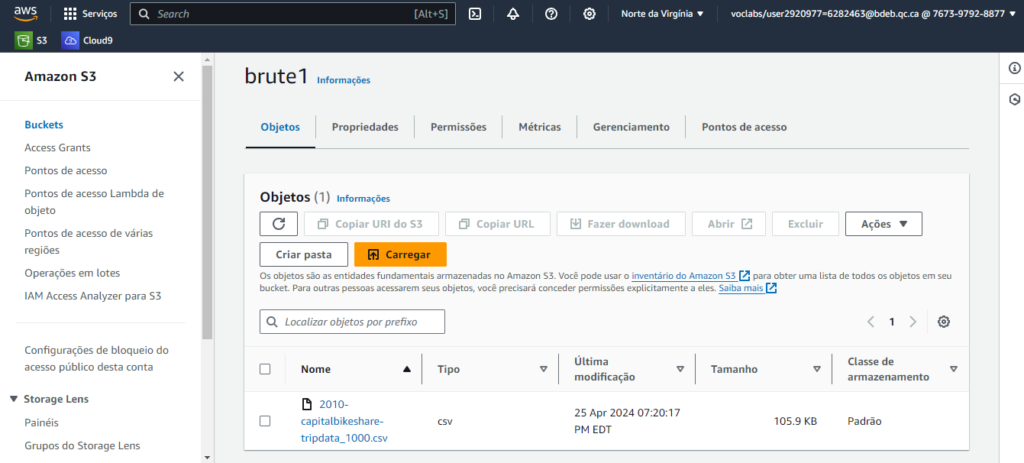
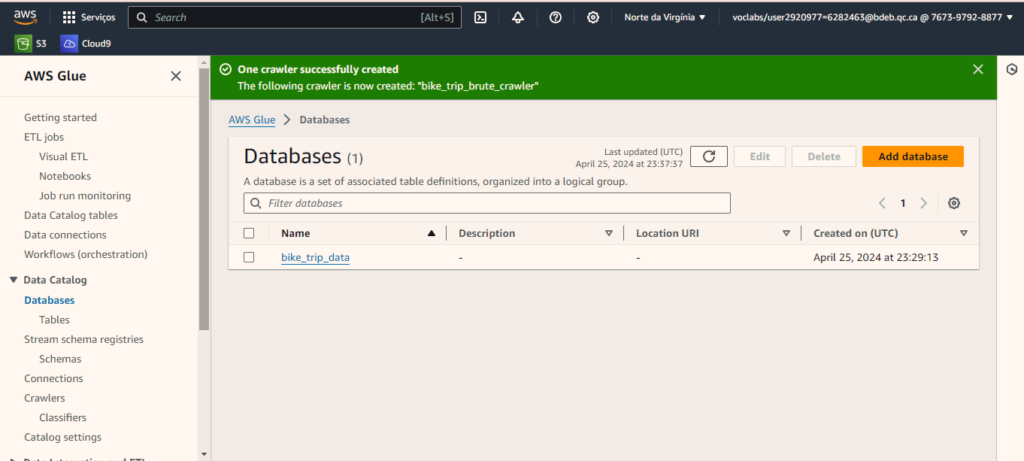
J’ai enregistré mon fichier dans une base de données, afin de pouvoir créer une « table » et je lui ai donné le nom de cette base de données bike_trip_data.
J’ai mis en place un pipeline simple pour déplacer et convertir les données de la zone brute vers la zone normalisée au format Parquet.
Si les données avec lesquelles je travaillais étaient en flux continu, streaming, il serait important de changer le format du fichier vers parquet pour plusieurs raisons, notamment:
Efficacité de stockage : Le format Parquet est optimisé pour le stockage et la compression des données. Il utilise des techniques de compression efficaces qui réduisent considérablement la taille des fichiers, ce qui permet d’économiser de l’espace de stockage.
Traitement efficace des requêtes : Parquet organise les données en colonnes, ce qui permet une lecture sélective des colonnes et une exécution efficace des requêtes. Cela se traduit par des temps de réponse plus rapides lors de l’exécution de requêtes sur de grands ensembles de données.
Traitement parallèle : Parquet prend en charge le traitement parallèle, ce qui signifie que plusieurs tâches peuvent être exécutées simultanément sur différentes parties du fichier. Cela permet d’exploiter pleinement les capacités de traitement parallèle des clusters de calcul, ce qui accélère le traitement des données.
Compatible avec Spark : Parquet est un format de fichier natif pour Spark, ce qui signifie qu’il est parfaitement intégré à l’écosystème Spark. Cela facilite le traitement des données Parquet dans Spark, ce qui permet d’exploiter pleinement les fonctionnalités avancées de Spark pour le traitement et l’analyse de données.
En ce qui concerne le streaming et le traitement dans Spark, Parquet présente également des avantages significatifs :
Traitement efficace du streaming : Parquet est adapté au traitement de flux de données dans Spark. Sa structure de fichier optimisée permet une ingestion et un traitement rapides des flux de données, ce qui le rend idéal pour les applications de streaming en temps réel.
Traitement distribué : Comme mentionné précédemment, Parquet prend en charge le traitement parallèle, ce qui le rend adapté au traitement distribué des flux de données dans Spark. Cela permet de distribuer efficacement la charge de travail sur plusieurs nœuds d’un cluster Spark, ce qui permet de traiter de grandes quantités de données de manière rapide et efficace.
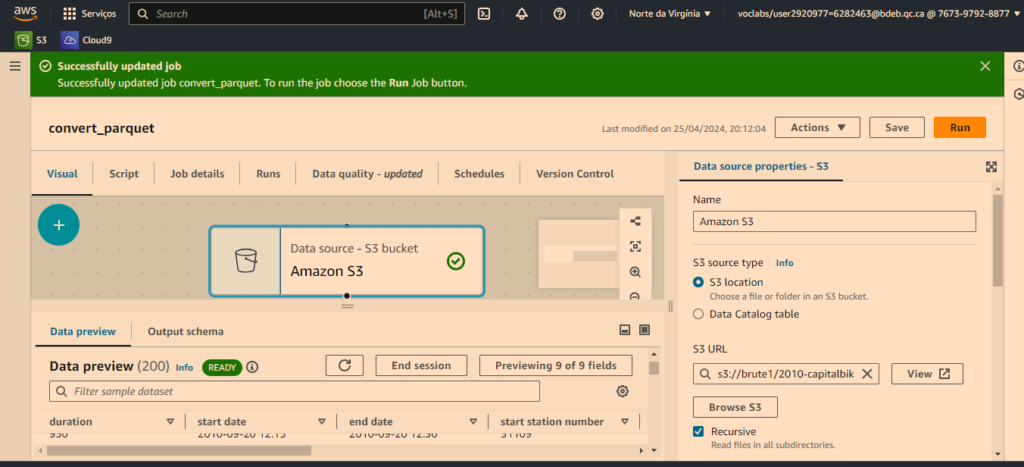
C’est est possible de modifier les types de données des ressources clés dans un schéma de données sur AWS Glue en utilisant la fonction « Modifier le schéma ». En modifiant le schéma de données, vous pouvez spécifier différents types de données pour les champs clés, comme changer de chaîne (str) à entier (int), par exemple.
Cette capacité de modifier les types de données des ressources clés est utile dans plusieurs situations, telles que :
Normalisation des types de données : Parfois, les données peuvent être stockées sous forme de chaînes, même si elles représentent des nombres. En changeant ces types de données pour le type correct (par exemple, entier), vous assurez la cohérence et la précision des données.
Optimisation des performances : L’utilisation du bon type de données peut améliorer les performances des requêtes et des opérations de traitement des données, en particulier lors du traitement de grands volumes de données.
Compatibilité avec les outils et les frameworks : Certains frameworks et outils d’analyse de données peuvent nécessiter des types de données spécifiques. En ajustant les types de données pour répondre aux exigences de ces outils, vous assurez l’interopérabilité et la compatibilité de votre système de données.
Il est important de faire attention lorsque vous modifiez les types de données, en veillant à ce que la conversion soit effectuée correctement et qu’il n’y ait pas de perte de données ou d’informations importantes pendant le processus. De plus, il est recommandé de faire des tests et des validations après la modification du schéma pour s’assurer que les données sont interprétées correctement.
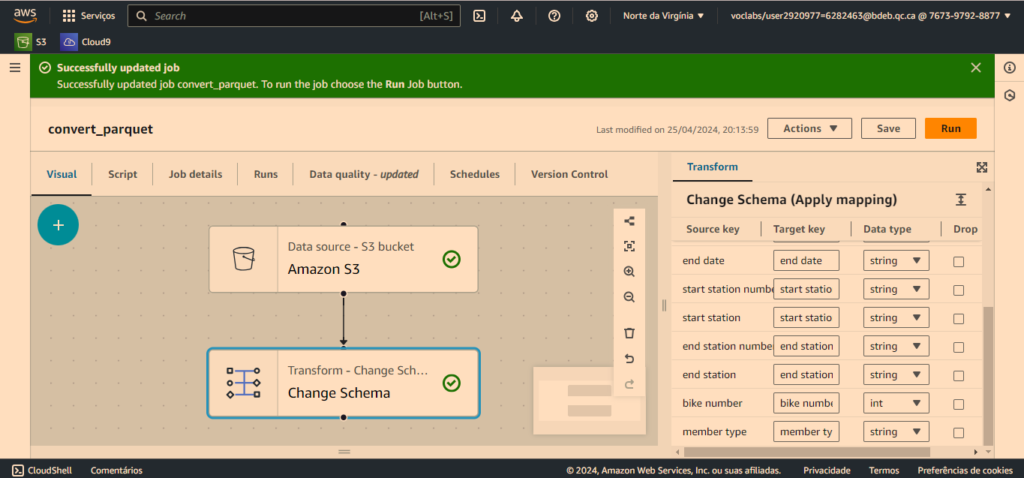
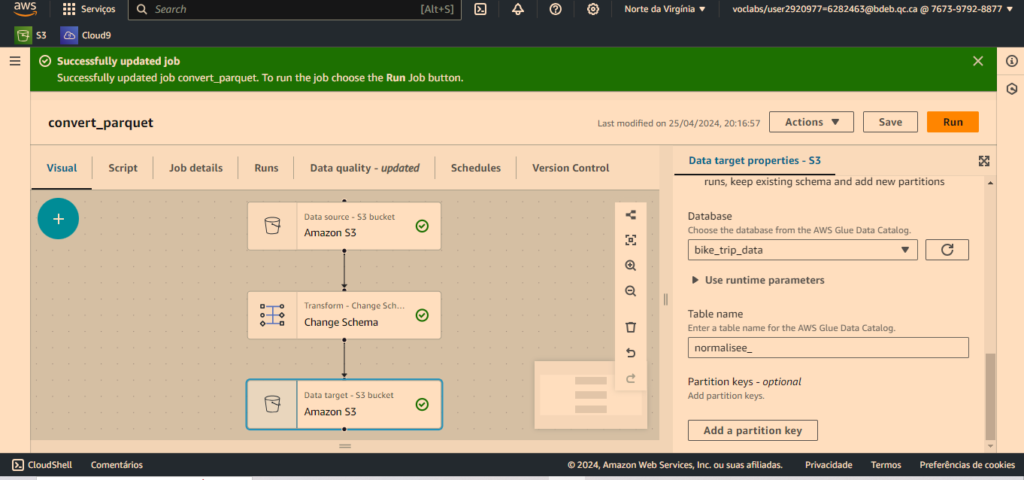
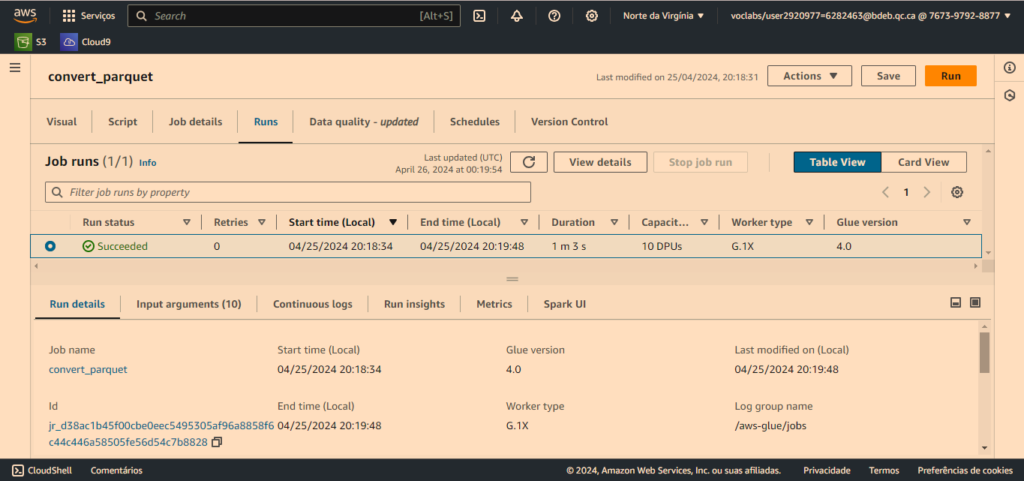
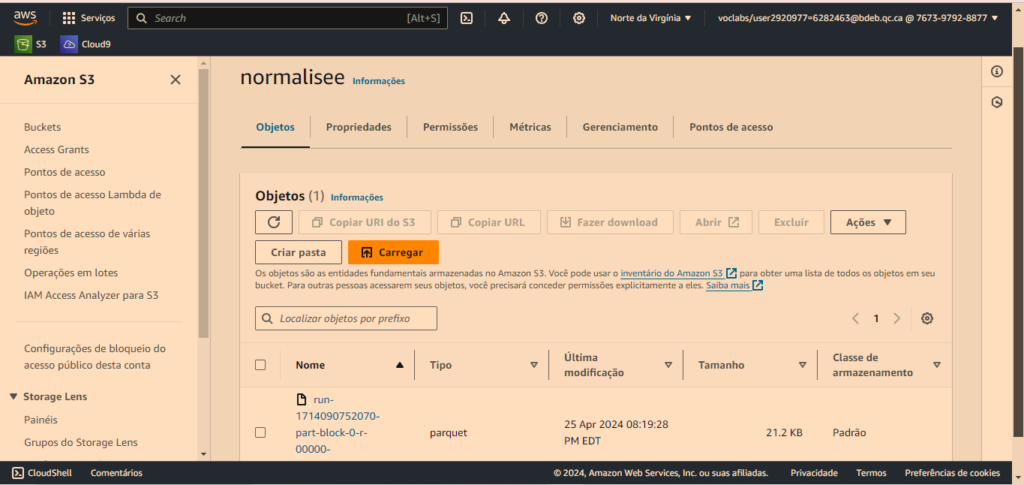
Vous pouvez constater le contenu de la zone normalisée une fois que le fichier parquet a été créé après exécution du pipeline
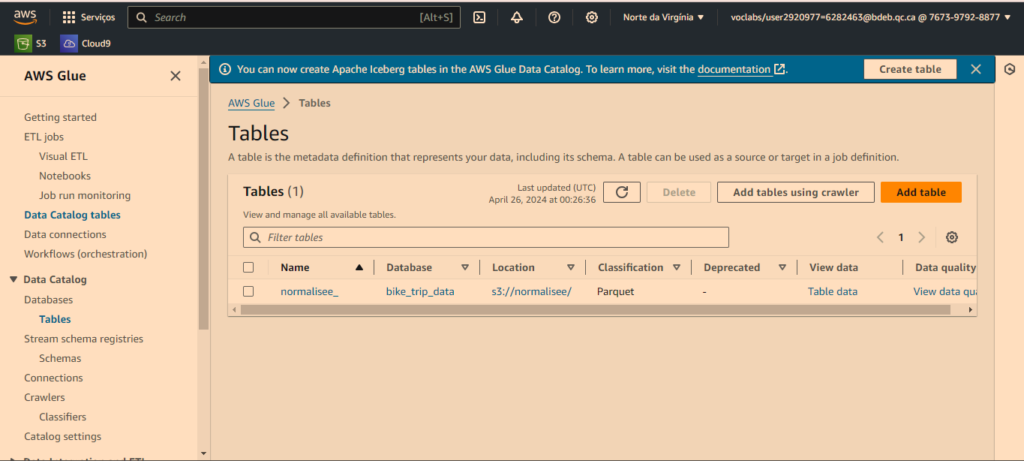
Et pourquoi ai-je également créé une « table » après avoir converti le fichier ?
Créer une table dans l’environnement AWS Glue présente plusieurs avantages pour le traitement et l’analyse des données :
Découverte Automatique des Données : AWS Glue peut effectuer la découverte automatique des données et de la structure des fichiers stockés dans des sources de données telles qu’Amazon S3. Cela simplifie le processus de définition de la structure de la table car Glue peut automatiquement inférer les schémas des données.
Catalogage Centralisé : AWS Glue dispose d’un catalogue de métadonnées centralisé qui stocke des informations sur les données, y compris les schémas, les emplacements et les formats. En créant une table dans Glue, vous enregistrez les métadonnées de la table dans le catalogue, ce qui facilite la découverte et l’accès aux données via d’autres services AWS.
Intégration avec les Services AWS : Les tables créées dans AWS Glue peuvent être facilement intégrées avec d’autres services AWS, tels qu’Amazon Athena, Amazon Redshift Spectrum et Amazon EMR. Cela permet d’exécuter des requêtes SQL et des analyses directement sur les données sans avoir besoin de les charger ailleurs.
Préparation des Données : AWS Glue offre des fonctionnalités pour la préparation des données, telles que les transformations ETL (Extract, Transform, Load). En créant une table dans Glue, vous pouvez définir des transformations et des nettoyages de données qui seront appliqués automatiquement lors du processus d’extraction et de chargement des données.
Gestion du Schéma : Glue permet de définir et de maintenir le schéma des données de manière centralisée. Cela garantit la cohérence et l’intégrité des données, facilitant la maintenance et l’évolution des pipelines de données.
En résumé, créer une table dans l’environnement AWS Glue offre un moyen pratique et efficace de cataloguer, préparer et accéder aux données dans les environnements de big data sur AWS, offrant ainsi une base solide pour les analyses et le traitement des données.
Après avoir compris les informations fournies ci-dessus, l’apprentissage de la création d’un ETL (Extract, Transform, Load) sur AWS Glue comprend :
Connaissance des services AWS : En utilisant AWS Glue pour l’ETL, vous vous familiarisez avec les services cloud d’AWS, apprenant à travailler avec le Glue Data Catalog, S3, Athena et d’autres services associés.
Compétence en catalogage et gestion des métadonnées : Vous apprenez à cataloguer et gérer les métadonnées des données en utilisant le Glue Data Catalog, ce qui est essentiel pour faciliter la découverte et l’accès aux données dans un environnement big data.
Expérience dans les transformations de données : En définissant et en exécutant des transformations de données sur AWS Glue, vous acquérez de l’expérience dans le nettoyage, l’enrichissement et la préparation des données pour l’analyse.
Compréhension des processus ETL : AWS Glue offre une interface visuelle pour créer et planifier des pipelines ETL, ce qui aide à comprendre les processus ETL et comment ils peuvent être automatisés et mis à l’échelle dans le cloud.
Capacité à intégrer différentes sources de données : Vous apprenez à intégrer et unifier des données provenant de différentes sources telles que des fichiers CSV, des bases de données relationnelles et semi-structurées, dans un data lake ou un data warehouse sur AWS.
Connaissance en optimisation des performances : En travaillant avec AWS Glue, vous gagnez en expérience dans l’optimisation des performances de vos pipelines ETL, en garantissant que les transformations de données s’exécutent de manière efficace et rapide.
En résumé, faire un ETL sur AWS Glue offre une expérience complète dans plusieurs domaines liés aux données dans le cloud, allant de la gestion des métadonnées à l’exécution des transformations de données et à l’optimisation des performances des pipelines ETL


Laisser un commentaire